
Sobre Tipos de Dados no Power Query
- Hugo Venturini

- 13 de ago. de 2024
- 5 min de leitura
Quando trabalhamos com fontes de dados semiestruturadas ou não estruturadas, no Power Query do Excel, ou no Power BI, a etapa de tratamento de dados mais importante é a da TIPIFICAÇÃO ou TIPAGEM, que é onde determinamos com qual tipo de dados estamos lidando, de acordo com sua natureza e finalidade: se texto, números ou datas.
Fontes de dados estruturadas, como bancos de dados, Data Warehouses, Data Marts, Data Lakes, ou outras arquiteturas nesta categoria, fornecem os dados já tipificados de acordo com sua origem.
Isto não acontece com fontes semiestruturadas, como arquivos XML ou JSON (resultantes de conexão com APIs, por exemplo); ou fontes não estruturadas, como arquivos de planilhas eletrônicas (Excel e Google Sheets), textos (CSV, TXT), e outros (PDF). Nestes casos, os dados são importados pelo Editor de Consultas do Power Query, por padrão, como texto sem formatação, o que corresponde a categoria “Qualquer”, que aparece na lista de tipos possíveis, nos comandos localizados nos menus superiores:

E como “ABC123” no botão de acesso ao comando, em cada coluna da tabela de dados:

Dados neste formato não servirão para cálculos, nem tampouco como filtros. São praticamente inúteis.
Para “compensar” isto, o Power Query dispõe de um recurso automático que identifica e estabelece o tipo do dado de acordo com os caracteres encontrados em cada coluna (campo), da base analisada, no momento da importação. Ela acontece em seguida a etapa automática de promoção dos cabeçalhos, outro aspecto comum em fontes de dados semiestruturadas ou não estruturadas.
Se há caracteres numéricos misturados à caracteres como “/” (barra) e “:” (dois-pontos), o dado é interpretado como DATA, HORA ou DATA/HORA e assim tipificado.

Se há caracteres numéricos somente, ou misturados a caracteres como “.” (ponto), e “,” (vírgula), então o dado é interpretado e tipificado como números decimais, valor monetário (decimal fixo), ou números inteiros.

Se há caracteres interpretáveis como true ou false, como “0” e “1” ou os próprios termos em si, então o campo é tipificado como valor lógico.
Quase todos os demais casos acabam tipificados como texto, por conter cadeias mais complexas de letras e símbolos:

Num primeiro momento, para o usuário iniciante no uso da tecnologia, este recurso de tipificação automática parece pura mágica, quase uma dádiva, uma vez que ele pode poupar muito tempo neste trabalho de tratamento de dados. E este usuário se sente até incentivado a utilizá-lo, uma vez que há até um botão específico para isto, chamado “Detectar Tipos de Dados”, presente no grupo de comandos “Qualquer Coluna”, do menu “Transformar”:

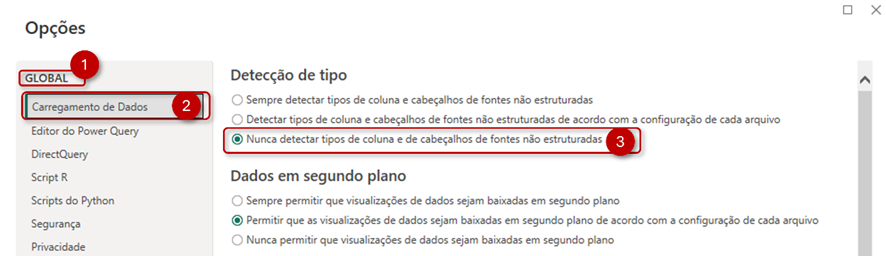
O meu conselho aos participantes em todos os treinamentos e cursos que ministro, é exatamente o oposto: para que o profissional NUNCA faça uso deste recurso, e configure o Power Query, seja no Excel ou no Power BI, para que não execute esta rotina automaticamente:

Para um tutorial completo sobre a configuração do Power BI Desktop ou do Power Query no Excel, acompanhe este outro artigo:
Para justificar tal postura, vou mostrar as consequências disto para nós, que vivemos e trabalhamos no Brasil, mas ressaltando que tais efeitos não se apresentam exclusivamente aqui, para nossa cultura.
O ponto mais crítico diz respeito à tipificação dos números. Em nosso sistema de padrões, usamos a vírgula como separador decimal. Em países como os EUA, é usado o ponto, caractere que, por sua vez, em nosso sistema, é simplesmente um separador de milhares, uma característica estética, e não determinante para o tipo numérico, se decimal ou inteiro:

Números no padrão brasileiro, mesmo sem tipagem.

Números no padrão americano, mesmo sem tipagem.
Neste cenário, o recurso de tipificação automática do Power Query gerará um erro de graves consequências, pois haverá um conflito entre os padrões, quando trabalharmos com arquivos de dados originados nos EUA, ou países que adotam igual padrão; ou até mesmo em arquivos CSV, criados aqui mesmo, mas que obedeçam ao padrão de utilização do caractere vírgula para separação de campos – o que obrigará que números decimais tenham o ponto como separador decimal.
O erro ocorre, pois, normalmente o Windows, o Power BI e o Excel, estarão instalados no computador em nosso idioma – Português do Brasil – obedecendo, portanto, os nossos padrões de escrita, mas a fonte de dados estará de acordo com outro padrão.
Ao fazer a tipificação de dados numéricos diretamente, considerando estas configurações, o mecanismo do Power Query considerará que o ponto, no meio da cadeia de caracteres numéricos da coluna, será um mero separador de milhares, não determinante para estabelecer o tipo como DECIMAL, nem obrigatório, esteticamente falando, e o excluirá convertendo o número em um INTEIRO, o que fará com que um número na ordem de grandeza de centena, por exemplo (observe atentamente a última imagem), se torne um número de ordem de grandeza de dezena de milhar.
Para imaginar a gravidade disto, imagine que tal coluna contém os valores de base de cálculo para impostos, por exemplo, e que sua solução se destina a apurar o montante a ser pago pela empresa, multiplicando tal base, pela respectiva alíquota do imposto em questão.
Algo semelhante acontecerá com datas, uma vez que o padrão americano também é diferente. Se estivermos tratando da data de vencimento de tal pagamento, o mesmo, na prática, provavelmente ocorrerá em atraso. Ou algum prazo poderá ser perdido em virtude de tal distorção.


Num mundo de economia globalizada, empresas que tramitam dados entre filiais alocadas em diferentes países, com diferentes culturas e padrões de medidas, é algo cada vez mais comum e frequente, o que também evidencia o risco do problema exposto.
O recurso de Detecção Automática de Tipo do Power Query, aplica os tipos como se estivéssemos escolhendo entre as possibilidades diretamente no menu acessível pelo botão do cabeçalho de cada coluna:

Quando deveria, em casos assim, usar a opção “Usando a Localidade”, para indicar o local de origem dos dados que estão sendo tratados, e possibilitar que o mecanismo faça a conversão, de acordo com os respectivos padrões: o de origem dos dados, e o da configuração da máquina em que o processo está sendo realizado.

Por isto, minha recomendação em cursos e treinamentos, desde sempre, e agora aqui também, em canal público, acessível a todos os interessados, é de que as configurações do Editor de Consultas do Power Query sejam alteradas, para que NUNCA detectem os tipos de dados para fontes não estruturadas.
Tipos de dados são um aspecto de absoluta importância, com impacto em todo o desenvolvimento da solução, e precisam, por isto, passar pelo crivo do profissional, que, bem-preparado, considerará todos os aspectos aqui mencionados, e executará o trabalho da forma correta.
Profissionais da área tecnológica, em virtude de seu escopo de estudos, costumam já se atentar para tais fatores desde cedo, porém, com cada vez mais profissionais enveredando para a área de análise de dados, oriundos de outras áreas de formação, se faz necessário alertar para tais riscos, e reforçar a importância de um treinamento de qualidade para aquisição de tais conhecimentos.

Comentários